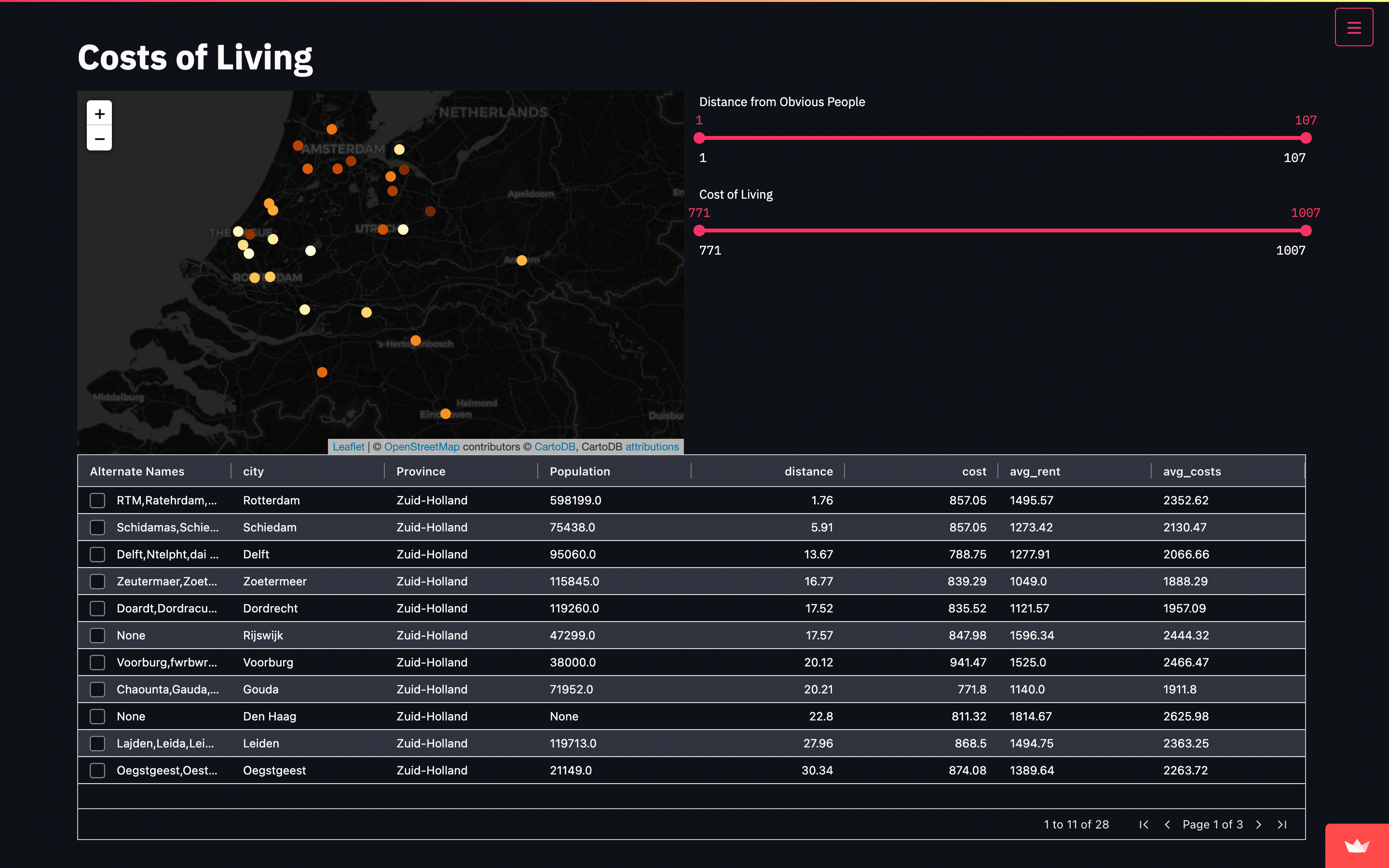
I wanted do relate Brazilian Zip code vs cities codes (IBGE). So I coded that below.
Source: https://github.com/erickmattoso/crawler_cep
# Import Libs
import json
import urllib
import requests
import pandas as pd
import numpy as np
pd.set_option('max_columns', None)
pd.set_option('float_format', '{:f}'.format)
# Data Ingestion
minha_lista = pd.read_csv('../data/raw/minha_lista.csv',index_col=0,low_memory=False).reset_index(drop=True)
ja_encontrados = pd.read_csv('../data/raw/cep_ibge.csv',low_memory=False).reset_index(drop=True)
nao_encontrado = pd.read_csv('../data/raw/nao_encontrado.csv',index_col=0,low_memory=False,names=['cep']).reset_index(drop=True)
# Adjust CEPs
# The CEP columns have the characteristic of `INT`. Let's transform it into a string and complete it with zeros
minha_lista['cep'] = minha_lista['cep'].map(int).apply(lambda x: '{0:0>8}'.format(x))
ja_encontrados['cep'] = ja_encontrados['cep'].map(int).apply(lambda x: '{0:0>8}'.format(x))
nao_encontrado['cep'] = nao_encontrado['cep'].map(int).apply(lambda x: '{0:0>8}'.format(x))
# Removing common values
# ## already found
# If the `ja_encontrados` table already contains the zip code we are looking for, there is no reason to search because we already have the information.
minha_lista = minha_lista[~minha_lista['cep'].isin(ja_encontrados['cep'])]
# ## not found
# If the `nao_encontrado` table already contains the zip code we are looking for, there is no reason to search because there is no way to find it.
# DELETE
# nao_encontrado = nao_encontrado.head (1)
minha_lista = minha_lista[~minha_lista['cep'].isin(nao_encontrado['cep'])]
# Settings to rotate
# Let's remove everything that is NAN
minha_lista = minha_lista.dropna()
# If this list contains special characters, we will adjust them
minha_lista['cep'] = minha_lista['cep'].str.replace("\.|\-|\,","")
# Let's tag everything that is not exclusively numeric
minha_lista['flg_cep'] = minha_lista['cep'].astype(str).str.isnumeric()
# We will keep records that are exclusively numeric
CEPs = minha_lista[minha_lista['flg_cep']==True].drop(['flg_cep'],1)
# If there are duplicate records, we will remove them here
CEPs = CEPs.drop_duplicates()
# Let's turn this result into a list
lista_ceps=list(CEPs['cep'])
# Recognizing CEP
# Let's run two apis. We will give priority to awesomeapi which is more complete and if not, we will look for it in postmon.
lista_ceps=list(CEPs['cep'])
# Let's create an array because that way we can save intermediate results.
meu_cep = np.array_split(lista_ceps, int(len(lista_ceps)/round(len(lista_ceps)/50)))
len(meu_cep)
# The function below must search the api for a zip code and return the IBGE code for that value
for i, cepzin in enumerate(meu_cep):
# list to save ibge / zip data
awesomeapi=[]
postmon=[]
# list to store ceps not found
error = []
# comment
for cep in (cepzin):
print(cep, end=" - ")
try:
resp = urllib.request.urlopen('https://cep.awesomeapi.com.br/json/'+cep)
awesomeapi.append(json.loads(resp.read()))
print("1")
except:
try:
url = ('https://api.postmon.com.br/v1/cep/'+cep)
postmon.append(requests.get(url, timeout=0.1).json())
print("2")
except:
error.append(cep)
print("3")
pd.DataFrame(awesomeapi).to_csv('../data/processed/temp/partial_awesomeapi_'+str(i)+'.csv')
pd.DataFrame(postmon).to_csv('../data/processed/temp/partial_postmon_'+str(i)+'.csv')
pd.DataFrame(error).to_csv('../data/processed/temp/partial_error_'+str(i)+'.csv')
# Reading the results
# aggregation junction of partial results
from pathlib import Path
def agregador(file=None, path='../data/processed/temp/'):
data_dir = Path(path)
df = pd.concat(
pd.read_csv(csv_file, index_col=0)
for csv_file in data_dir.glob(file+'*'))
return df
awesomeapi = agregador(file='partial_awesomeapi_')
awesomeapi = awesomeapi.drop_duplicates()
postmon = agregador(file='partial_postmon_')
postmon = postmon.drop_duplicates()
error = agregador(file='partial_error_')
error = error.drop_duplicates()
# Saving backup
from shutil import copyfile
from datetime import datetime
dt_string = datetime.now().strftime("%d_%m_%Y_%H_%M_%S")
try:
copyfile('../data/raw/cep_ibge.csv', '../data/processed/cep_ibge_' + dt_string + '.csv')
copyfile('../data/raw/minha_lista.csv', '../data/processed/minha_lista' + dt_string + '.csv')
copyfile('../data/raw/nao_encontrado.csv', '../data/processed/nao_encontrado' + dt_string + '.csv')
except:
print('erro')
pass
# Saving results
awesomeapi.to_csv('../data/processed/awesomeapi.csv')
postmon.to_csv('../data/processed/postmon.csv')
error.to_csv('../data/processed/nao_encontrado.csv')
# postmon
postmon['estado_info'] = postmon['estado_info'].fillna("{}")
postmon['cidade_info'] = postmon['cidade_info'].fillna("{}")
import ast
postmon["cidade_info"] = postmon["cidade_info"].map(lambda d : ast.literal_eval(d))
postmon = pd.concat([postmon.drop(['cidade_info'], axis=1), postmon['cidade_info'].apply(pd.Series)], axis=1)
try:
postmon = postmon[['bairro', 'cidade', 'cep', 'estado','codigo_ibge', 'logradouro']]
except:
postmon['logradouro']=np.nan
postmon = postmon[['bairro', 'cidade', 'cep', 'estado','codigo_ibge', 'logradouro']]
postmon
postmon = postmon.rename(columns={
'bairro':'district',
'cidade':'city',
'estado':'state',
'logradouro':'address',
'codigo_ibge':'city_ibge',
})
postmon
# ## resultado final
ja_encontrados = pd.read_csv('../data/raw/cep_ibge.csv',index_col=0,low_memory=False)
resultado_final = pd.concat([ja_encontrados,awesomeapi],0)
resultado_final.head()
resultado_final = pd.concat([resultado_final,postmon],0).reset_index(drop=True)
resultado_final['cep'] = resultado_final['cep'].map(int).apply(lambda x: '{0:0>8}'.format(x))
resultado_final.tail()
# Salvar
resultado_final.to_csv('../data/raw/cep_ibge.csv')
error.to_csv('../data/raw/nao_encontrado.csv')