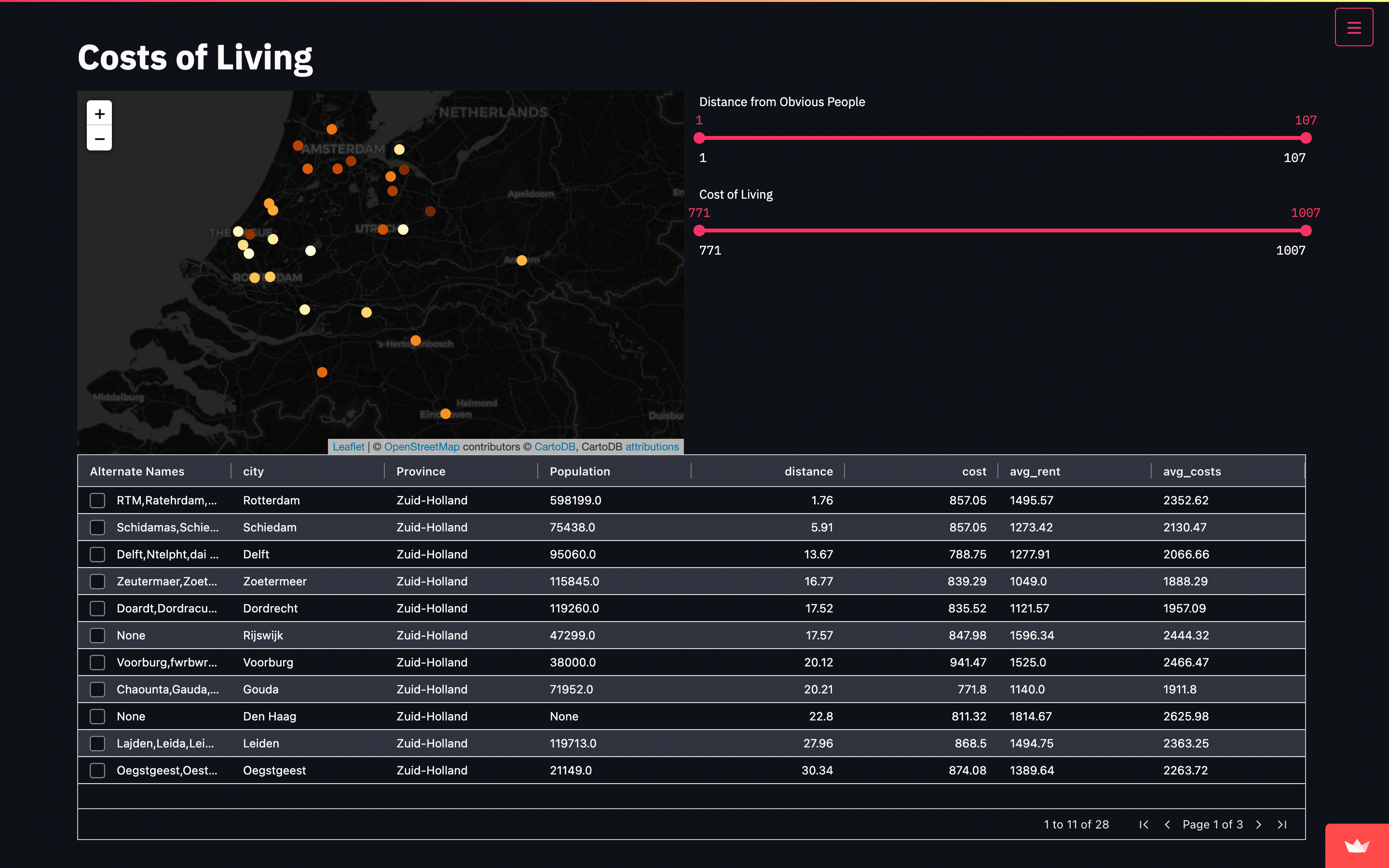
In order to mitigate price errors and maintain more accurate control of the stock, a Crawler was carried out that scanned the entire site and presented the prices and stocks available at that time. The high quantity of skus, but with limited stock was a problem that the customer faced. With the solution presented, price anomalies were pointed out and we managed to maintain a high accuracy in Sony Brasil’s inventories.
Source: https://github.com/erickmattoso/cr_sony/
from bs4 import BeautifulSoup
from itertools import chain
from datetime import datetime
import json
import pandas as pd
import requests
import urllib.request
import os
def run_crawler(filename, website, sheetnamed, sku):
json_list = []
website = website
sheetnamed= sheetnamed
for i in sku:
try:
resp = urllib.request.urlopen('https://'+website+'.sony.com.br/produto/sku/' + str(i))
json_list.append(json.loads(resp.read()))
print('working(y) - https://'+website+'.sony.com.br/produto/sku/' + str(i))
except KeyboardInterrupt:
print('Bye!')
break
except:
print('working(n) - https://'+website+'.sony.com.br/produto/sku/' + str(i))
pass
dataframe = pd.DataFrame(list(chain.from_iterable(json_list)))
df_sku = dataframe['SkuSellersInformation'].to_list()
df_sku = pd.DataFrame(list(chain.from_iterable((df_sku))))
df_sku = df_sku[['AvailableQuantity','IsDefaultSeller','Name','SellerId']]
df_complete = pd.concat([dataframe, df_sku], axis=1)
df_complete['Reference'] = (df_complete['Reference'].str.replace('\/.*', '', regex=True).str.lower())
df_complete['link'] = 'https://store.sony.com.br/' + df_complete['Reference'] + "/p"
df_complete['%'] = 1 - (df_complete['Price'] / df_complete['ListPrice'])
df_complete['date'] = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
df_master = pd.read_excel(r"C:\Users\Graziela Baranzelli\Desktop\Arquivo Comprimido\master.xls", sheet_name=sheetnamed, parse_dates=['DATEFROM'])
df_merged = pd.merge(df_complete,df_master, left_on='Id', right_on='SKU')
df_merged['PREÇO CARTÃO 10X'] =round(df_merged['PREÇO CARTÃO 10X'],2)
df_merged['PREÇO "DE"'] =round(df_merged['PREÇO "DE"'], 2)
short = df_merged[['Availability','AvailableQuantity','Id','Reference','Name','Name','link','ListPrice','Price','PriceWithoutDiscount','%','date', 'PREÇO CARTÃO 10X','PREÇO "DE"','DATEFROM']].copy()
short['variacao_preco_barato'] = short['Price'] - short['PREÇO CARTÃO 10X']
short['variacao_preco_caro'] = short['ListPrice'] - short['PREÇO "DE"']
file1=r"C:\Users\Graziela Baranzelli\Desktop\Arquivo Comprimido\content\sku.csv"
df_complete[['Id']].to_csv(file1)
excel_file = filename
writer = pd.ExcelWriter(excel_file, engine='xlsxwriter')
short.to_excel(writer, sheet_name='short')
workbook = writer.book
worksheet = writer.sheets['short']
worksheet.conditional_format('S2:S9999', {'type': '3_color_scale'})
worksheet.conditional_format('T2:T9999', {'type': '3_color_scale'})
df_merged.to_excel(writer, sheet_name='df_complete')
workbook = writer.book
worksheet = writer.sheets['df_complete']
writer.save()
writer.close()
print("done")
print("0 = store")
print("1 = corporativostore")
position1 = int(input('Digite o website: '))
print()
print("0 = skus conhecidos")
print("1 = buscar todos os skus")
position2 = int(input('Escolha: '))
website = ['store','corporativostore']
sheetnamed = ['B2C','B2B2C']
file1=r"C:\Users\Graziela Baranzelli\Desktop\Arquivo Comprimido\content\sku.csv"
sku = [list(pd.read_csv(file1)['Id']), range(0,3333)]
website = website[position1]
sheetnamed = sheetnamed[position1]
sku1 = sku[position2]
file2=r"C:\Users\Graziela Baranzelli\Desktop\Arquivo Comprimido\sku_sony_"+website+".xlsx"
run_crawler(file2, website, sheetnamed,sku1)