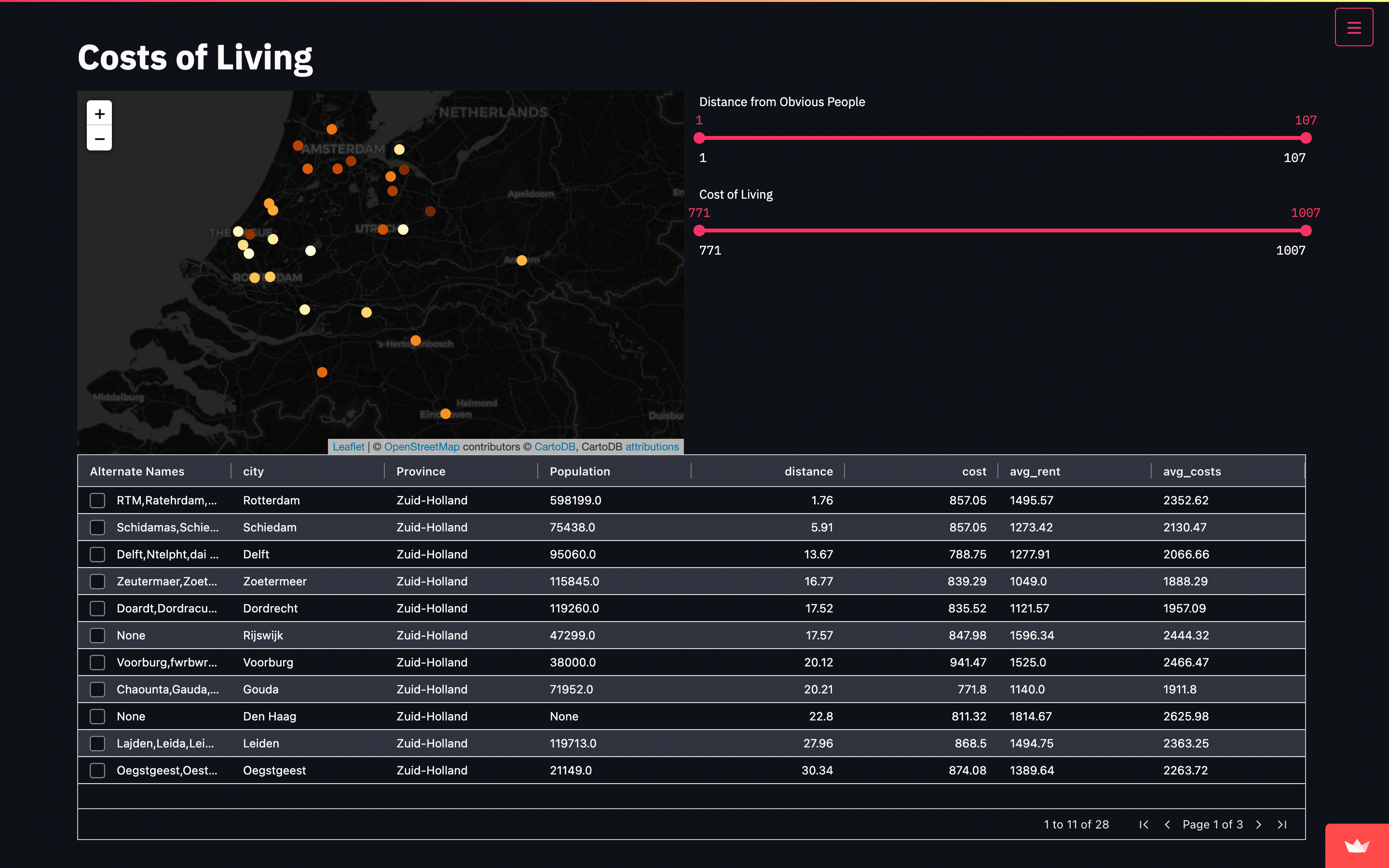
Here is my code to download multiple images from multiples pages from Magalu Store.
Source: https://github.com/erickmattoso/cr_magalu/
# Web Crawler
# A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the internet to Web indexing (web spidering). Here in my tests I am going to use magazine luiza store to get information and download some images. For help me on that, I am also using the library BeautifulSoup and urllib.
# Import the necessary libraries
# from urllib.parse import urlparse
# from urllib.request import urlopen
# import csv
# import math
# import pandas.io.formats.excel
# import urllib
# pandas.io.formats.excel.header_style = None
from bs4 import BeautifulSoup
from openpyxl import load_workbook
from openpyxl.workbook import Workbook
from urllib.parse import urljoin
from urllib.request import urlretrieve
import os
import pandas as pd
import re
import requests
import xlsxwriter
# Here are my functions
def extract_title(content):
# get soup and choose lxml parser
soup = BeautifulSoup(content, 'lxml')
# if title tag has text so return it
tag = soup.find('title', text=True)
# if title tag hasn't text so return none
if not tag:
return None
return tag.string.strip()
def extractMax(value):
# replace characters
string = value.replace(".", "")
# replace characters
string = string.replace(",", ".")
# remove string and keep just numbers
number = re.findall(r'-?\d+\.?\d*',string)
return float("".join(number))
def extract_old_price(content):
# get soup and choose lxml parser
soup = BeautifulSoup(content, 'lxml')
# if it finds a class, return its content
tag = soup.select_one('.price-template__from')
# if it does not find return none
if not tag:
return None
return extractMax(tag.string.strip())
def extract_new_price(content):
# get soup and choose lxml parser
soup = BeautifulSoup(content, 'lxml')
# if it finds a class, return its content
tag = soup.select_one('.price-template__text')
# if it does not find return none
if not tag:
return None
return extractMax(tag.string.strip())
def extract_all_links(content):
# get soup and choose lxml parser
soup = BeautifulSoup(content, 'lxml')
# set same as list, but it does not have duplicate values
links = set()
# find all links in a tag 'a' that starts with some rule and add to a "list" called links
for tag in soup.find_all('a', href=True):
if tag['href'].startswith('https://www.magazineluiza.com.br/'):
links.add(tag['href'])
return links
def extract_showcase_link(content):
# get soup and choose lxml parser and choose lxml parser
soup = BeautifulSoup(content,'lxml')
# find the link in a tag 'img' inside some class and get its src
image_tags = soup.findAll('img', {"class":"showcase-product__big-img"})
for image_tag in image_tags:
return(image_tag.get('src'))
def download_showcase_img(content):
# get soup and choose lxml parser and choose lxml parser
soup = BeautifulSoup(content, 'lxml')
# find the link in a tag 'img' inside some class
imgs = soup.findAll("img", {"class":"showcase-product__big-img"})
# download img
for img in imgs:
# get the src of the img
img_url = urljoin(content, img['src'])
# it split all src link and get the final part to create the name of the file
file_name = img['src'].split('/')[-1]
# save this file on a folder called "img/"
file_path = os.path.join("img/", file_name)
# actually downloads the img
urlretrieve(img_url, file_path)
# Crawler
def crawl(content):
# get the first link and add to a list and, with set, ask to do not repeat the same url
seen_urls = set([content])
# get the first link and add to a list and, with set, ask to do not repeat the same url
available_urls = set([content])
# create a workbook, there is no need to create a file on the filesystem to get started with openpyxl,
## just import the workbook class and start work
wb = Workbook()
# a workbook is always created with at least one worksheet, you can get it by using the workbook.active
page = wb.active
# name of the sheet
page.title = 'products'
# header names list
headers = [
'product',
'old_price',
'new_price',
'discount',
'description',
'showcase_link',
'product_link']
# add header names list to our xlsx
page.append(headers)
# save xlsx file
workbook_name = 'magalu_raw.xlsx'
wb.save(filename = workbook_name)
# start a counter to present found product links
counter = 1
# select an existing excel file
wb = load_workbook(workbook_name)
# Crawler
while available_urls:
# all available url should be tested
url = available_urls.pop()
try:
# if it takes up to 3 seconds, so continue and add to a content variable
content = requests.get(url, timeout=3).text
except Exception:
continue
print(str(counter) + ": " + url)
counter+=1
# for a link found, it should pass on extract_all_links
for link in extract_all_links(content):
# new link
if link not in seen_urls:
# add to a list of visited links
seen_urls.add(link)
# add to a list of available links to do the looping
available_urls.add(link)
# if it finds a page with a price extract_new_price then it save data
if(extract_new_price(content)):
# if it finds a old price then it create the discount variable
if(extract_old_price(content)):
discount = (1-(extract_new_price(content)/extract_old_price(content)))
# if it does not finds a old price then it return None
else:
discount = None
# pages with tag price download showcase img
download_showcase_img(content)
# select an existing excel sheet file
page = wb.active
# select data to save on an existing excel sheet file
lines = [
(extract_title(content)),\
(extract_old_price(content)),\
(extract_new_price(content)),
discount,
(extract_title(content)),\
(extract_showcase_link(content)),\
url]
# add on an existing excel sheet file
page.append(lines)
#save on an existing excel sheet file
wb.save(filename=workbook_name)
# print the title of this page
print("It is a product: " + extract_title(content)[0:51])
# start a counter to present found product links
# Starting Page
# get contents from url
webpage = 'https://www.magazineluiza.com.br/smartphone-motorola-g7-play-32gb-indigo-4g-2gb-ram-tela-57-cam-13mp-cam-selfie-8mp/p/155549300/te/mtgp/'
# get contents from url
page = requests.get(webpage)
# Running crawler
# Start the crawler
try:
crawl(webpage)
# Stop the while
except KeyboardInterrupt:
print()
print('Bye!')
# Format excel file
# read the excel file
df = pd.read_excel (r'magalu_raw.xlsx')
# organize 'discount' data in descending order
df = df.sort_values(by=['discount'],ascending=False)
# create a document called magalu_formated
writer = pd.ExcelWriter('magalu_formated.xlsx', engine='xlsxwriter')
# create a sheet called products
df.to_excel(writer, sheet_name='products')
# write in a sheet called products
worksheet = writer.sheets['products']
# format
worksheet.conditional_format('E2:E999', {'type': '3_color_scale','min_color': "green",'max_color': "red"})
# save it
writer.save()